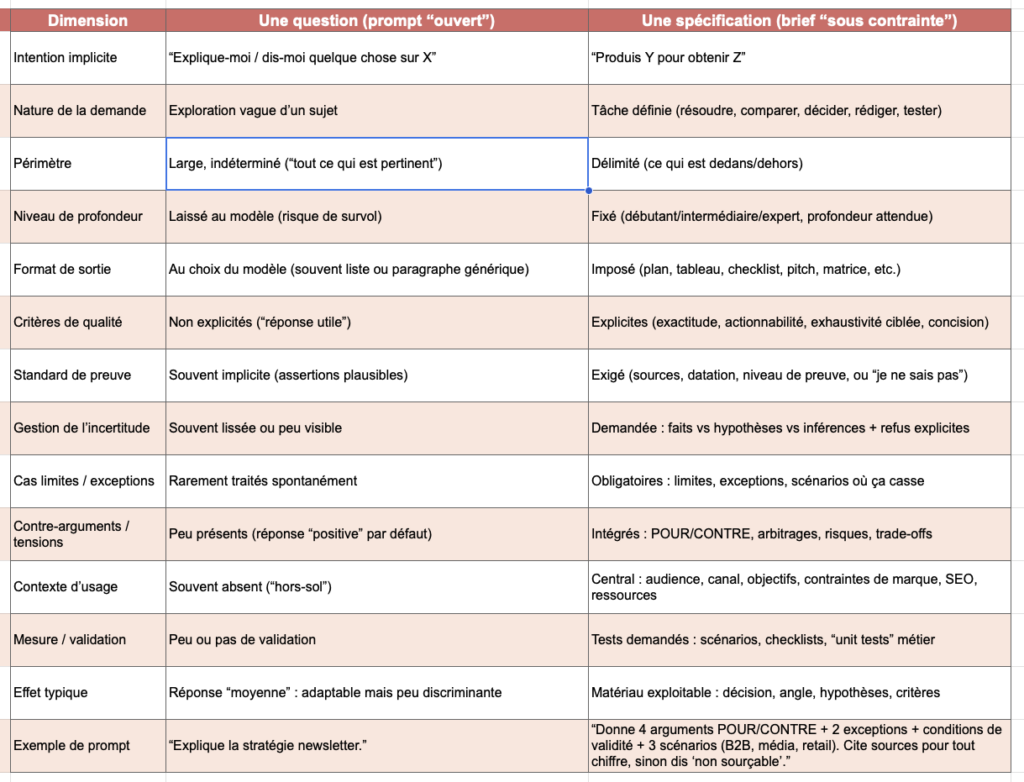
Dans les usages “content generation”, on parle souvent du prompt comme d’une requête (“Écris-moi un article sur…”). En réalité, c’est plus proche d’un brief : une spécification minimale qui dit au modèle quoi produire, pour qui, dans quel cadre, avec quels critères.
Si le brief est incomplet, le modèle comble les trous avec des choix par défaut. C’est une conséquence mécanique parce que le modèle doit quand même produire une réponse “cohérente” (il a été entrainé pour cela).
C’est là que naît une impression de “moyennisation” : le modèle converge vers une sortie générique, consensuelle, peu risquée, parce que c’est ce qui a statistiquement le plus de chances d’être acceptable dans beaucoup de contextes.
Pourquoi les prompts ouverts produisent des réponses « par défaut »
Un prompt ouvert (ex. “Explique-moi le sujet X”) laisse trois décisions clés au modèle :
- le niveau de profondeur (survol vs détail),
- le périmètre (ce qui est dedans / dehors),
- le standard de preuve (assertions, exemples, sources, prudence).
Quand ces dimensions ne sont pas fixées, la réponse tend à être lissée. Ce lissage n’est pas qu’une impression : dans un cadre mesuré (résumés de recherche scientifique), des travaux montrent un biais d’“overgeneralization” : les modèles étendent plus souvent que des humains la portée des conclusions au-delà de ce que dit le texte source (odds ratio ~4,85, et sur-généralisation observée jusqu’à 73% des cas selon les modèles et conditions).
Transposé au content : un prompt ouvert produit facilement des formulations “valables partout” (donc mémorisables, donc recyclables), et évite les zones où un rédacteur métier fait la différence : conditions, seuils, exceptions, arbitrages.
Novice vs connaisseur : l’asymétrie n’est pas l’expertise, c’est le cadrage
Grosso modo “un prompt pointu alimente l’expertise”, si on entend “pointu” comme : capable de cadrer une tâche éditoriale.
Un utilisateur content expérimenté (ie. qui connait son sujet) apporte souvent, même implicitement :
- une intention (éclairer / trancher / comparer / convaincre),
- un angle (ce qui est vraiment en jeu),
- des contraintes (ton, longueur, niveau, marque),
- un standard de qualité (preuves, exemples, sources, limites).
Ce cadrage compte : des résultats récents sur l’impact de la spécificité du prompt (mesurée et comparée) concluent que, globalement, augmenter la spécificité améliore la performance, en particulier sur des tâches procédurales et de raisonnement.
Autrement dit : l’utilisateur “connaisseur” n’obtient pas une meilleure IA. Il réduit l’espace des réponses possibles, et force le modèle à se comporter comme un assistant de travail, pas comme un générateur de texte.
Challenger l’IA : explorer les tensions plutôt que consommer une réponse
Un usage content mature consiste moins à “demander un texte” qu’à demander au modèle de mettre un raisonnement sous contrainte. Ce qui change tout : on ne cherche pas une réponse, on cherche une carte du problème.
1) Prompt « ouvert » vs « tension »
Exemple : Version prompt « ouvert »
“Fais un article sur les bénéfices de la newsletter pour une marque.”
Le modèle va sortir une liste attendue. Bateau.
Version “tension” :
Objectif : produire un angle éditorial solide (pas un listing).
Tâche : donne 4 arguments POUR la newsletter et 4 arguments CONTRE.
Pour chaque argument : un exemple concret + une condition de validité (quand ça marche) + un risque (quand ça casse).
Si un argument dépend du secteur, explicite les secteurs typiques.L’intérêt n’est pas la symétrie des opinions. C’est la mise en évidence des conditions : ce que la newsletter suppose (audience, fréquence, distribution, proposition de valeur) et ce qu’elle déplace (CRM, contenu, attribution). Ces conditions enrichissent considérablement la réponse.
2) Limites
Toujours côté content, une limite utile est souvent une limite de transposabilité : ce qui est vrai en B2C ne l’est pas en B2B ; ce qui marche pour une marque média ne marche pas pour une DNVB.
Prompt :
Liste 6 limites ou conditions d'échec de cette stratégie.
Classe-les : (a) limites structurelles, (b) limites organisationnelles, (c) limites de mesure.
Ajoute pour chaque limite un signal faible observable en amont.On obtient des signaux actionnables (ex. “la promesse éditoriale n’est pas stable”, “le canal n’est pas instrumenté”, “la fréquence est incompatible avec le cycle de production”).
3) Exceptions
Le point fort du rédacteur métier, c’est l’exception pertinente : celle qui invalide une recommandation trop générale.
Prompt :
Donne 5 exceptions : des cas où la recommandation classique est contre-productive.
Pour chaque exception : explique le mécanisme (cause → effet) en 3 phrases max.Cette approche force le modèle à quitter le “centre” et à se confronter à des situations frontières.
Conditions de fiabilité : transformer une sortie en matériau exploitable
Challenger le modèle ne suffit pas. Il faut aussi définir ce qu’on considère comme “fiable” dans un contexte content.
Sources : datation et niveau de preuve
Ce qui compte : demander des sources ne sert à rien si on ne demande pas quoi sourcer et comment.
Prompt :
Pour chaque fait chiffré ou affirmation causale, indique :
- une source primaire si possible (étude, doc officielle) ou sinon secondaire,
- l'année,
- ce qui est mesuré exactement (définition / métrique),
- et ce qui n'est PAS couvert.
Si tu ne peux pas sourcer, dis-le explicitement.Ce type de contrainte est cohérent avec les recommandations générales de prompting (contexte, structure, séparation instructions / contenu, expliciter le format).
Tests : scénarios, cas limites, “unit tests” éditoriaux
Dans le content, un “test” peut être simple : vérifier que l’argument tient dans 3 situations.
Prompt :
Propose 3 mini-scénarios (B2B SaaS, média, retail) et réévalue la recommandation dans chacun.
Si ta réponse change, dis ce qui change et pourquoi.Ce mécanisme réduit le risque de conseils “copier-coller”.
Exemples : chercher des contrastes, et non des illustrations
Un bon exemple n’illustre pas. Il différencie.
Prompt :
Donne 2 exemples opposés (un où ça marche, un où ça échoue).
Même format pour les deux : contexte, décision, résultat, facteur clé.Refus explicites : rendre visible l’incertitude
Une des techniques les plus productives en pratique consiste à autoriser (et exiger) le “je ne sais pas” :
Ajoute une section "Ce que je ne peux pas conclure avec les infos disponibles".
Liste 5 questions dont la réponse conditionne la recommandation.Ce n’est pas un détail de confort : c’est une façon de forcer le modèle à séparer faits, inférences et hypothèses, et à expliciter ses dépendances (ce que recommandent aussi des guides de gestion du risque d’hallucination en contexte professionnel).
Le prompt comme discipline éditoriale, pas comme incantation
On peut dire que les prompts ouverts “moyennisent” au sens où ils laissent le modèle choisir la granularité, le périmètre et le standard de preuve — donc il revient vers des sorties par défaut, adaptables, mais peu discriminantes.
À l’inverse, un prompt “pointu” n’est pas un prompt technique. C’est un prompt qui contraint : il impose des tensions (contre-arguments, limites, exceptions) et des conditions de fiabilité (sources, tests, exemples, refus explicites). C’est moins une compétence d’IA qu’une compétence humaine.
Ce raisonnement suppose une chose : que la valeur attendue n’est pas “un texte prêt à publier”, mais un matériau de décision (angles, hypothèses, risques, cadrage). Dès qu’on change cette attente, le prompt cesse d’être un bouton, et redevient ce qu’il est : un outil de travail.
Sources
- Étude sur le biais de sur-généralisation dans les résumés scientifiques
- Synthèse grand public de cette étude
- Travaux sur l’impact de la spécificité du prompt
- Recommandations de prompting (structure, séparation instructions/contexte, spécificité)
- Gestion du risque d’hallucination en contexte professionnel