Ca fait un moment que je cherche une solution au casse-tête de la mesure du GEO. Je suis allé piquer des idées du coté du Brand Concept Mapping.
En SEO, on a longtemps optimisé des pages pour des mots clés. En GEO, on optimise des marques pour des réponses. Or ces réponses sont rédigées à la volée et personnalisées par les Chatbots en fonction d’entités. Partant de ce constant j’essaie de reconstruire des indicateurs adaptés aux relations marque-entité-concept. Et de proposer un outil que je vous invite à tester : GPT Brand Concept Scoring* (je suis preneur de feedbacks)
Logique de ranking (SEO) vs logique de relation (GEO)
Pendant 25 ans, l’outillage SEO s’est construit sur une hypothèse stable : on compare des volumes de recherche, on surveille des positions, on mesure des taux de clics. Tout cela a produit une grammaire opérationnelle très efficace… tant que la performance dépendait d’une correspondance explicite entre mots clés et résultats.
Un outil de contrôle SEO classique peut vous dire si vous couvrez un champ lexical, ou si une page ranke sur « assurance auto pas chère ». Il est beaucoup moins capable de dire si votre marque est conceptuellement alignée avec : “simplicité sans friction”, “contrat transparent”, “assistance réactive”, “preuve de fiabilité”, et comment ces concepts se structurent entre eux.
Un LLM n’explore pas un index par mots-clés. Il manipule des entités et des relations : produits, usages, besoins, bénéfices, preuves, valeurs, tonalités, signaux de crédibilité. Quand un moteur génératif répond, il ne restitue pas un classement ; il recompose une cartographie implicite de ce qui est central, cohérent, crédible et distinctif dans un domaine. Ceci afin de générer une réponse personnalisée.
En résumé je dirais que :
« Le GEO vise à augmenter la probabilité qu’une marque soit associée aux bons concepts dans une réponse générée et que cette association soit stable dans le temps. »
Renaud JOLY
Définition du Brand Concept Scoring
On peut avoir un contenu très bien optimisé coté mots-clés et être conceptuellement diffus. Pour le contrôler le GEO l’idée est de se baser sur un calcul de Brand Concept Scoring basé sur le concept du Brand Concept Mapping.
Le définition du Brand Concept Scoring est :
Le Brand Concept Scoring mesure la force d’une marque via une cartographie de concepts présents dans un LLM et un score de proximité marque–concept, centralité, différenciation, preuve, cohérence.
Le Brand Concept Scoring est intéressant parce qu’il part du bon objet : la marque. Il n’essaie pas d’inférer une visibilité à partir de prompts synthétisés. Mon GPT Brand Concept Scoring s’interdit explicitement Google, SEO, parts de marché et popularité web. Il s’impose une comparaison uniquement à partir des entités et concepts associées à la marque.
Quels sont les concepts utilisés et leurs qualifiants ?
Le Brand Concept Scoring se base sur une cartographie d’environ 100 concepts par marque (nombre limité afin d’éviter une dispersion de l’analyse), structurée par niveaux N1–N7 :
- N1–N2 : univers et catégories produits
- N3 : fonctions & usages
- N4 : bénéfices rationnels
- N5 : bénéfices émotionnels
- N6 : service, expérience, relation
- N7 : valeurs, preuves, crédibilité (“reasons to believe”)
Il attribue ensuite à chaque concept quatre qualifiants qui, traduits en GEO, correspondent aux quatre questions qu’un système génératif se pose implicitement : centralité, différenciation, preuve, hygiène.
Le Brand Concept Scoring s’inscrit dans la logique suivante :
- pas d’analyse du ranking de pages sur des mots-clés (vous continuez votre SEO par ailleurs)
- analyse d’un positionnement de marque comme architecture de concepts
- scoring qui reflète la proximité marque-concept, et non la couverture lexicale
- comparaison inter-marques à modèle constant : mêmes niveaux sémantiques, mêmes coefficients, mêmes contraintes de volume
Dans un environnement génératif, la bataille n’est pas seulement d’être classé, mais d’être attribuable. Une marque présente sans différenciation devient un nom parmi d’autres. Une marque attribuable devient une référence associée à un faisceau de concepts (et donc de réponses potentielles).
Comment lire les qualifiants ?
Voici ce que signifie chaque qualifiant et comment l’interpréter dans les tableaux.
Centralité
C’est la place du concept dans la marque.
- Cœur : concept structurant de la promesse de marque. Si on l’enlève, la marque change d’identité.
Ex. réussir ses projets, le contrat de confiance. - Pilier : gros contributeur à la valeur perçue, très présent et répétable. Sans lui la marque s’affaiblit nettement, mais reste elle-même.
Ex. logistique, cuisine, stock, expérience digitale. - Support : renforce les piliers (améliore l’expérience, réduit les frictions) mais n’est pas déterminant seul.
Ex. tutos, aides au choix, options de livraison, accessoires. - Périphérique : utile pour certains segments/ occasions, mais marginal dans l’architecture de marque.
Ex. domotique nice to have, inspiration déco légère.
Impact scoring : Cœur = poids max, Périphérique = poids faible.
Différenciation
C’est la capacité à distinguer la marque de ses concurrents.
- Banal : attendu partout, non différenciant, quasi commodité.
Ex. retours possibles. - Standard : normal pour la catégorie, la plupart des acteurs l’ont.
Ex. stock, SAV, gammes peinture. - Distinctif : plus marqué que la moyenne, perçu comme un vrai plus, mais copiable.
Ex. découpe bois, outils projet, filtres de recherche performants. - Signature : associé spontanément à la marque, élément identitaire difficile à confondre.
Ex. promesse projet + services
Impact scoring : Signature = coefficient max, Banal = coefficient bas.
Preuve
C’est la capacité de la marque à porter le concept sans avoir besoin de données externes. Prouve à quel point le concept est crédible dans le récit de marque.
- Forte : concept tangible et vérifiable par l’expérience service concret, fonctionnalité, dispositif clair.
Ex. click and collect, découpe en magasin, plan 3D. - Moyenne : plausible mais dépend de l’exécution, qualité variable, pas toujours garantie.
Ex. conseil en magasin, pose partenaires. - Faible : plutôt un ressenti / aspiration, difficile à démontrer sans preuve additionnelle.
Ex. prix juste, plaisir, confiance, tendance.
Impact scoring : Forte = gros multiplicateur, Faible = pénalité.
Hygiène
C’est un facteur de pondération lié au marché qui permet d’ajuster les poids.
- Hyg. (Hygiénique) : indispensable dans la catégorie, tout le monde l’a. C’est une évidence ça compte moins dans la puissance de marque.
Ex. stock minimum, retours, gammes de base. - Neutre : ni obligatoire ni exclusif, le poids est normal.
- Sign (Signature) : rare ou propre à la marque. Le poids est augmenté car ça construit l’avantage compétitif.
Impact scoring : Hygiénique = réduit, Signature = boost.
Comment lire une ligne complète ?
Voici le format des données dans les captures du cas pratique à suivre.
“Plan 3D cuisine — Pilier — Signature — 0.90 — Forte — Sign”
Le plan de cuisine en 3D est :
- très important pour la marque (Pilier)
- fortement différenciant (Signature)
- cohérent avec la promesse (0.90)
- crédible / tangible (Forte)
- signature marché (Sign)
Cette entité sera donc très contributrice au score.
Cas pratique dans le secteur de bricolage
Que révèle la GPT Brand Concept Scoring ?
Secteur choisi complètement au hasard… 🙂
Pour Leroy Merlin, Castorama, et ManoMano, le GPT Brand Concept Scoring nous donne les résultats suivants :



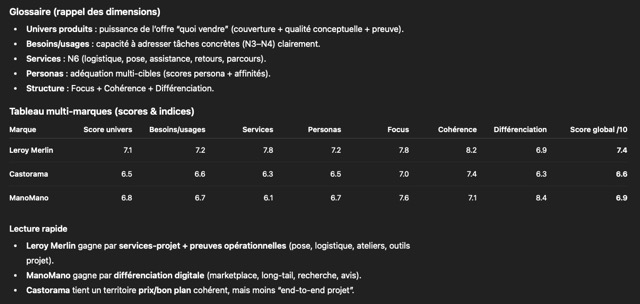
Alors oui je travaille pour Leroy Merlin et non je n’ai pas triché 🙂
Il y a d’autres tableaux, le plus simple est de tester le GPT Brand Concept Scoring* (je reste preneur de feedbacks).
Pourquoi ces scoring peuvent varier ?
Il peut y avoir des écarts entre deux scorings conceptuels même faits à peu d’intervalle. Le score n’est pas une mesure factuelle, mais une agrégation de choix de modélisation : concepts retenus, niveaux N1–N7, hygiène/signature, pondérations personas, etc. Ainsi de petites variations en amont créent vite des écarts en aval. Mais nous sommes habitués au caractère probabiliste des LLM, n’est ce pas ?
Voici un liste des causes les plus fréquentes de ces écarts :
- Changement implicite de périmètre
- Set de concepts différent (80–120) = moyenne différente
- Reclassification en Hygiénique / Neutre / Signature (multiplicateur)
- Différences sur Centralité / Différenciation / Preuve (coefficient)
- Personas et affinités différentes
- Effet “dilution” vs “focus”
Pour comparer à l’identique entre 2 scoring conceptuels différents il faudrait verrouiller ces 6 paramètres.
Comment utiliser le BCS pour améliorer son GEO ?
L’intérêt opérationnel n’est pas de calculer un score. C’est d’identifier des leviers actionnables sur ce que les réponses génératives vont retenir, condenser et réattribuer.
1) Renforcer le noyau conceptuel
L’outil calcule donc un indice de Focus (concentration sur concepts cœur/pilier vs dispersion). En GEO, la dispersion est un problème structurel : une marque dispersée produit des réponses floues.
Un Focus faible indique souvent :
- trop de périphérie
- trop de standards
- pas assez de répétition structurée du cœur
Le levier contenu, ici, n’est pas l’addition de nouveaux sujets, mais la densification : répéter, articuler, relier le cœur à des preuves et à des cas d’usage.
2) Transformer la différenciation en attribution par des signatures prouvées
Un concept distinctif mais preuve faible est un signal classique : l’idée est bonne mais la crédibilité n’est pas installée. En GEO, c’est précisément le type de concept qui demande des contenus preuves :
- démonstrations
- mises en situation
- explicitation de l’expérience (N6)
- raisons de croire (N7)
L’objectif n’est pas d’être convaincant, mais d’être réutilisable : une réponse générée réutilise plus facilement une proposition quand elle est liée à des signes tangibles.
Ex : « Support 24/7 par chat et téléphone, temps de réponse moyen annoncé, suivi des demandes dans un espace client. » au lieu de « Le service le plus fiable du marché. »
3) Clarifier les tensions de cohérence
Le score intègre un coefficient de cohérence (0–1). En pratique, les incohérences sont des générateurs de bruit : elles produisent des réponses instables ex : “la marque est X… mais aussi Y”, ou des synthèses diluées.
Le GEO bénéficie d’une marque dont les concepts N5–N7 (émotion, relation, valeurs, preuves) ne contredisent pas les univers N1–N4 (produits, usages, bénéfices).
4) Piloter par persona sans basculer dans la segmentation artificielle
Le prompt autorise jusqu’à 8 personas, avec des scores “pourquoi”. En GEO, cela sert à une chose : vérifier que les concepts cœur / pilier ne sont pas seulement “généraux”, mais qu’ils s’attachent à des usages réels.
Une marque peut être cohérente et pourtant abstraite. Les personas ramènent l’architecture conceptuelle à des critères de choix, donc à des formulations susceptibles d’apparaître dans une réponse.
Ex : Comment fait-on pour choisir ?
Nul doute que ces leviers gagneront à être développés dans un prochain post.
Ce que le Brand Concept Scoring apporte au GEO
Si on résume, l’outil joue trois rôles dans le GEO :
- Audit de proximité marque–concept : ce que la marque dit d’elle-même et ce qui la distingue, structuré et comparable.
- Détection des faiblesses de crédibilité : où la promesse excède la preuve, et où la preuve manque d’expression.
- Architecture de renforcement : où concentrer les contenus et les campagnes pour maximiser attribution et stabilité.
Le gain est de stabiliser des concepts, de les hiérarchiser, de les prouver, et de les rendre distinctifs. C’est exactement ce que demande le GEO.
Qualifier et prouver la marque
Le contrôle du GEO est bien différent de contrôle du SEO car les LLM ne sont pas des moteurs recherche. La recherche est un déplacement, la réponse une reformulation.
Le Brand Concept Scoring oblige à répondre à une question que le SEO permettait parfois d’éviter : “Qui suis-je (quels concepts) et qu’est-ce que je peux prouver ?”.
Le Brand Concept Scoring formalise cette question en qualifiants : centralité, différenciation, preuve, hygiène, cohérence. Il mesure une capacité à être résumé dans des réponses pertinentes sans être trahi.
Et dans un environnement où la réponse précède le clic, cette capacité devient une action stratégique.
* Un abonnement ChatGPT Plus est nécessaire pour accéder aux GPT personnalisés