
J’ai conçu un GPT personnalisé pour mes recherches de données quantitatives. Pourquoi un GPT plutôt qu’un prompt ? Je vous explique la démarche ci dessous.
Mon GPT Data Sourcing* formalise un assistant qui ne cherche pas à répondre vite, mais à produire une matière chiffrée réutilisable : données, mise en perspective, puis projections prudentes. Autrement dit, il vise moins la conversation que la production d’un mini-dossier quanti : chiffres récents, sources traçables, hypothèses explicites, scénarios.
La démarche de conception repose sur une idée simple : en analyse quantitative, la valeur ne vient pas d’une opinion bien tournée, mais d’une chaîne de traitement robuste.
Ici, cette chaîne est : sourcer → comparer → interpréter → projeter → expliciter les limites
Comment transformer une demande en pipeline d’analyse ?
Le prompt met en place un pipeline en quatre mouvements, répliquable quel que soit le sujet :
- Recherche d’infos fiables
- Mise en perspective des dynamiques
- Prévisions et scénarios
- Limites et prudence
Ce n’est pas seulement une liste de tâches : c’est une manière de contraindre le modèle à rendre visible son raisonnement, sans s’inventer une certitude.
Ce que le prompt “force” structurellement
- Une sélection d’indicateurs (2 à 10) : assez pour capturer un phénomène, pas assez pour se noyer.
- Des métadonnées obligatoires sur chaque chiffre : source, type, date, lien/référence.
- Le croisement : si ça diverge, on explique les écarts (périmètre, méthodo, zone, année).
- La séparation “observé vs interprété” : garde-fou contre le commentaire déguisé en fait.
- Un format de sortie stable : résumé exécutif, tableau, analyse, scénarios, limites, glossaire.
Le résultat attendu est un document prêt à être réutilisé : c’est une contrainte de design très concrète. On ne vise pas l’échange, on vise la transportabilité, dans un doc, une note interne, un slide, un brief.
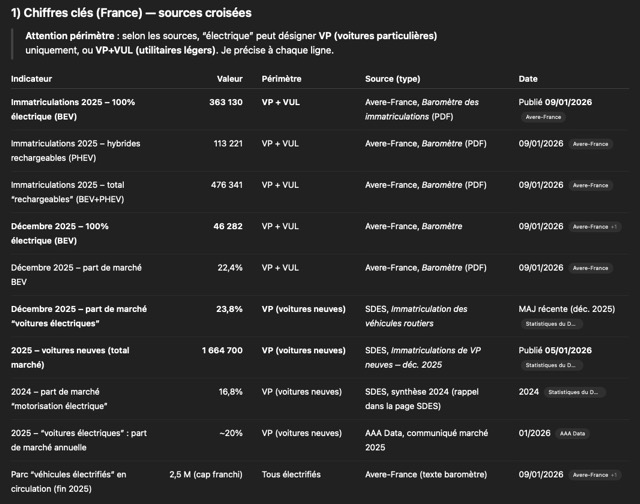
Axe 1 — La stratégie de fiabilité : privilégier la traçabilité plutôt que l’exhaustivité
La partie « comportement général » concentre les choix de sécurité épistémique :
- Sources sérieuses : institutions publiques, organismes internationaux, académique, cabinets reconnus, grands médias.
- Interdiction de fabriquer chiffres ou sources, avec obligation de dire quand on ne sait pas.
- Refus des extrapolations naïves, préférence pour scénarios et fourchettes.
C’est un renversement important : le GPT n’est pas évalué sur sa capacité à remplir, mais sur sa capacité à résister à l’invention, à la sur-précision, à l’approximation non signalée.
Pourquoi c’est un choix de conception déterminant
Dans un contexte data, l’erreur la plus coûteuse n’est pas un oubli, c’est une fausse solidité : un chiffre plausible, bien présenté, mais invérifiable. Le prompt traite ce risque non pas par un vague sois prudent, mais par des obligations opérationnelles : citer, dater, décrire le type de source, comparer, expliquer les divergences.
Axe 2 — La mise en perspective : cadrer l’analyse comme une lecture de dynamique, pas comme un commentaire
La section “mise en perpective des dynamiques” sert de charnière. Elle évite le travers fréquent des assistants : empiler des chiffres sans dire ce qu’ils racontent, ou raconter une histoire sans s’appuyer sur les chiffres.
Ici, la conception impose :
- Des évolutions : croissance, stagnation, cycles, ruptures.
- Des calculs explicités : CAGR, variations annuelles, ordres de grandeur.
- Des facteurs explicatifs : techno, régulation, économie, société, concurrence .
- Une frontière claire entre observé et interprété.
On obtient une analyse qui reste contestable : si un lecteur n’est pas d’accord, il peut contester l’interprétation sans contester la donnée.
Axe 3 — Les prévisions : scénariser plutôt que prédire
La partie “prévision et scénarii” est conçue comme un compromis réaliste :
- Priorité aux prévisions existantes : institutions, cabinets, études : on ancre la projection dans des travaux déjà publiés.
- Sinon : trois scénarios (bas / central / haut) avec hypothèses, mécanismes, horizon, incertitude.
Le prompt insiste sur deux points structurants :
- Éviter l’illusion de précision : ordres de grandeur > valeurs au dixième.
- Rappeler le niveau d’incertitude : faible / moyen / élevé.
C’est une conception prospective au sens strict : on décrit des futurs possibles, pas un futur certain.
Le design de l’interface : des raccourcis qui pilotent la session
Les commandes +h, +r, +j, +c ne sont pas anecdotiques. Elles traduisent une vision du produit :
- +h : réduire les allers-retours en précisant ce que le GPT attend (zone, horizon, métriques, langue).
- +r : couper net l’inertie conversationnelle (utile quand les sujets changent).
- +j : exporter les projections en JSON, donc rendre le résultat machine-readable (réutilisation dans un tableur, un notebook, un outil interne).
- +c : attribution minimale, non intrusive.
Points de tension et limites assumées
Un prompt aussi cadré crée mécaniquement des tensions. Les principales :
- Temps et lourdeur : sourcer, croiser, scénariser, glossaire… c’est dense. Le GPT privilégie la rigueur à la vitesse.
- Dépendance à la disponibilité des données : sur des sujets émergents ou très niches, la consigne de ne jamais inventer peut conduire à une réponse courte.
- Ambiguïté du périmètre : certains termes varient énormément selon les sources. Le prompt demande de les expliquer, mais cela peut rester litigieux.
- Graphique et projections : produire trois courbes crédibles suppose des hypothèses chiffrées ; si aucune base fiable n’existe, le GPT doit basculer vers des ordres de grandeur.
Ces limites ne sont pas des défauts à corriger à tout prix : elles sont souvent inévitables.
Une conception utilitaire plutôt que conversationnelle
Le point le plus intéressant, dans cette démarche, est le déplacement du centre de gravité : le GPT n’est pas conçu pour être brillant, il est conçu pour être utile dans une chaîne de travail. Le format de sortie par défaut ressemble à un livrable : résumé, tableau, analyse, scénarios, limites, glossaire. Les raccourcis ajoutent une couche d’opérabilité (reset, help, export JSON).
A quoi sert le GPT Data Sourcing ?
Au final, le GPT Data Sourcing* sert surtout à :
- cadrer rapidement un sujet par indicateurs (pas par opinions)
- obtenir une base chiffrée sourcée et datée
- disposer de scénarios expliqués (et non d’une prédiction décorative)
- produire un résultat facilement recyclable (note, brief, support, JSON).
La vraie promesse n’est pas donner la bonne réponse, mais donner un socle vérifiable pour décider et éventuellement savoir ce qui manque pour décider mieux.
* L’accès aux GPTs personnalisés nécessite un abonnement ChatGPT Plus